场景方案
Kafka 可以与其他的软件平台集成一起使用,解决 微服务架构 过程中的各种场景问题。
Kafka 与 Zookeeper
ZooKeeper 在 Kafka中起什么作用?
为了弄清Kafka和ZooKeeper的关系,我们需要先搞清楚以下几个名词:
- Broker:Broker是Kafka实例,每个服务器上有一个或多个kafka的实例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号。
- Producer:Producer即生产者,消息的产生者,是消息的入口。
- Topic:消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic。
- Partition:Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹!
- Replication:每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
- Message:每一条发送的消息主体。
- Consumer:消费者,即消息的消费方,是消息的出口。
- Consumer Group:我们可以将多个消费组组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
- Zookeeper:Kafka集群依赖ZooKeeper来保存集群的的元信息,简单来说ZooKeeper用于管理和协调Kafka代理。
Zookeeper在Kafka中的作用罗列如下:
-
Broker注册 每个Kafka服务器(即Broken)相互之间是独立的,那怎么把所有Broker作为集群来管理呢?Zookeeper有一个注册系统,专门用来进行Broker服务器列表记录的节点:/brokers/ids。每个Broker在启动时,都会到Zookeeper上进行注册,即到/brokers/ids下创建属于自己的节点,如/brokers/ids/[0...N]。Kafka使用了全局唯一的数字来指代每个Broker服务器,不同的Broker必须使用不同的Broker ID进行注册,创建完节点后,每个Broker就会将自己的IP地址和端口信息记录到该节点中去。其中,Broker创建的节点类型是临时节点,一旦Broker宕机,则对应的临时节点也会被自动删除。
-
Topic注册 在Kafka中,同一个Topic的消息会被分成多个分区并将其分布在多个Broker上,这些分区信息及与Broker的对应关系也都是由Zookeeper在维护,由专门的节点来记录,如:/borkers/topics。 Kafka中每个Topic都会以/brokers/topics/[topic]的形式被记录,如/brokers/topics/login和/brokers/topics/search等。Broker服务器启动后,会到对应Topic节点(/brokers/topics)上注册自己的Broker ID并写入针对该Topic的分区总数,如/brokers/topics/login/3->2,这个节点表示Broker ID为3的一个Broker服务器,对于"login"这个Topic的消息,提供了2个分区进行消息存储,同样,这个分区节点也是临时节点。
-
消息消费进度Offset记录 在消费者对指定消息分区进行消息消费的过程中,需要定时地将分区消息的消费进度Offset记录到Zookeeper上,以便在该消费者进行重启或者其他消费者重新接管该消息分区的消息消费后,能够从之前的进度开始继续进行消息消费。Offset在Zookeeper中由一个专门节点进行记录,其节点路径为:/consumers/[group_id]/offsets/[topic]/[broker_id-partition_id],节点内容就是Offset的值。
-
消费者注册 消费者服务器在初始化启动时加入Consumer Group,注册到消费者分组。每个消费者服务器启动时,都会到Zookeeper的指定节点下创建一个属于自己的消费者节点,例如/consumers/[group_id]/ids/[consumer_id],完成节点创建后,消费者就会将自己订阅的Topic信息写入该临时节点。
-
Leader选举 Zookeeper主导Kafka的Leader选举,选举过程过程比较复杂,这里不详细论述。这里主要说下选举的时机
- 集群初始化启动时选举
- 热加载了新的Kafka节点时
- Leader节点挂掉的时候了解决方法
Zookeeper用来管理Kafka,它没和生产者发生关系,只和消费者发生关系,如下图:
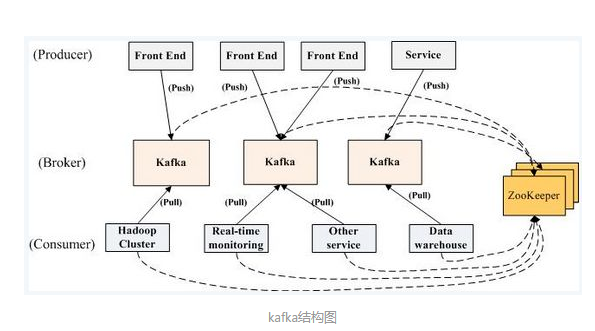
生产者如何找到Leader分区的呢?
Kafka集群时,每个Kafka节点都是对等,是通过Zookeeper对不同的topic选举出Leader分区。生产者发送消息时,如何知道哪个节点是Leader分区呢? 简单描述一下步骤:
- 生产者程序启动后,第一次发元数据请求,发给任意一台,都会返回所有元数据信息,包含你需要信息的Leander分区在哪里
- 生产者将Leader分区缓存下来,当发送消息时,就从缓存找到Leader分区,直接将消息发送给Leader分区
- 假如经过一段时间,增加了新的kafka服务器,导致leader分区重新选举,生产者不知情还继续将消息发送给之前的那个分区,这时会返回失败信息。这时将重复1,2保证能正常发送信息。