进阶
Docker 是云原生的基石,它对云原生的推动力等同于第一次工业革命时期蒸汽机的作用。
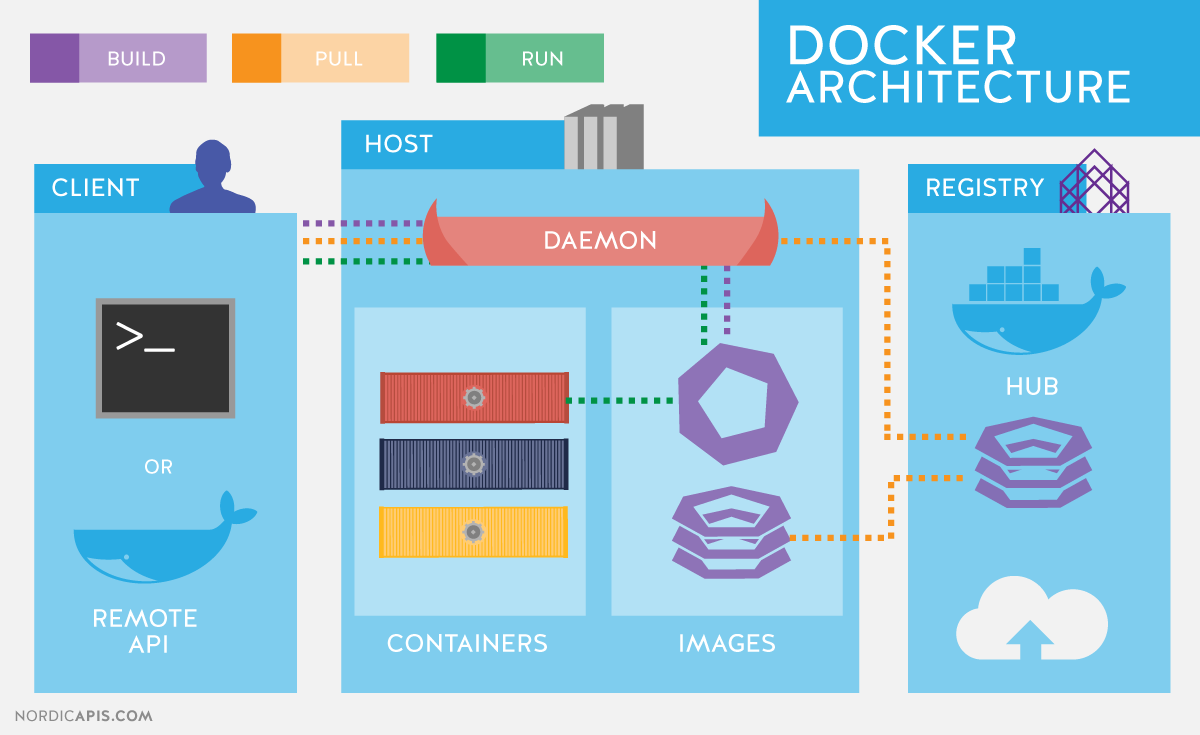
Docker 需要重点掌握的内容包括:
- 核心原理
- 基础三大件:镜像、容器、仓库
- 镜像生产:通过 Dockerfile 编排镜像所需的资源
- 持久化存储:将容器的数据保存在宿主机磁盘中
- 端口与互联:容器与宿主机、容器与容器、容器与外部的连接与通信机制
- 用户权限:容器中的用户与宿主机的用户之间的关系
- 编排:通过多容器互联,实现所需的业务场景
Docker 官方文档非常完善,而且非常有层次结构。
概念与原理
原理
轻量级虚拟机
Docker 是利用 Linux **虚拟隔离技术(namespace)**将操作系统分割为多个子操作系统,子操作系统之间互不干扰的一种虚拟化技术。
为什么会出现 Docker 技术? 其实主要有两个原因:
- 软件架构复杂化,一个应用需要多个虚拟机协作支撑的情况已经非常普遍(也可以理解为微服务化)
- 传统的操作系统笨重(占用 10G 左右的存储空间)、启动速度太慢(大约 20s)
也就是说,现在的系统架构,要求需要大量运行速度极快,资源占用甚少的轻量级虚拟机。
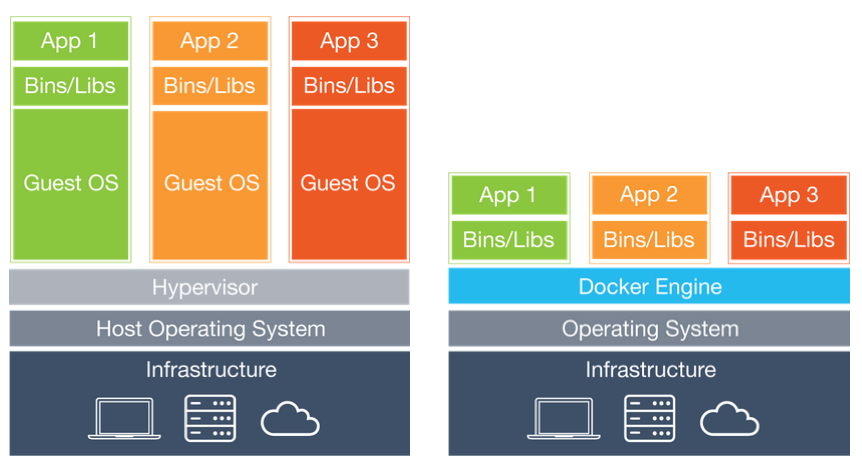
Docker 的出现,正好解决了上述的困扰,轻量化的虚拟机改变了系统架构,云原生诞生于此。
虚拟隔离
Docker 的核心原理可以归纳为两点:虚拟文件系统+虚拟用户。
什么意思呢?
- 虚拟文件系统本质上还是宿主机上的文件,但通过虚拟技术就变成了一种“独占”资源。
- 虚拟用户本质上还是宿主机上的用户,但通过虚拟技术让容器认为自己有了单独的用户管理。
仅有虚拟还不够,在技术上必须有隔离方可确保容器之间互不干扰。
Docker 是对操作系统资源进行虚拟组合,形成一种新的有边界子操作系统。
再回过头来澄清两个概念:
- 宿主机:运行 Docker 系统的那台虚拟机,被称之为宿主机
- 容器:通过 Docker 创建的轻量级虚拟机,被成为容器(Container)
以应用的角度看,容器与宿主机不是从属关系,而是并列关系
Docker 容器是一台真实的虚拟机,这是理解容器的关键。
容器虚拟机拥有传统虚拟机的一切功能和操作方式,只有这样才能跳出“技术陷阱”,直接借鉴虚拟机的技术原理来掌握容器技术。
容器存在的根本目前也是用于运行软件,既然是运行软件,同样需要:
- 安装基础环境
- 与外部互联
- 被外界访问
- 存储数据
- 存储代码
- 高可用
- 负载均衡
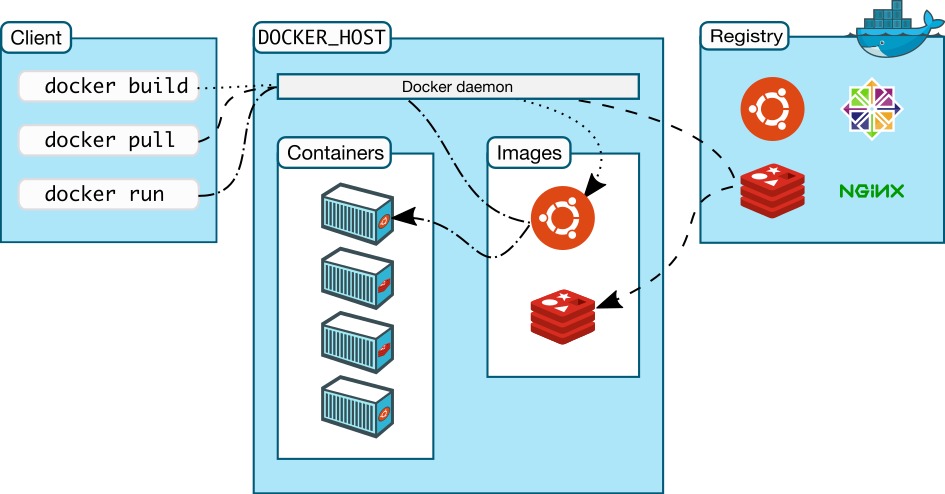
镜像
文件
Docker 的镜像是 Docker 容器运行的基础,镜像是一种文件的形态。
如果只考虑 Docker 容器的操作系统属性,那么镜像=轻量级操作系统安装包。
如果需考虑 Docker 容器的应用软件属性,那么镜像=(轻量级操作系统+应用)安装包
例如:MySQL 镜像= 虚拟的 Linux 操作系统 + MySQL
镜像是怎么产生的?
用户编写镜像编排 Dockerfile,对这种文件进行 build 操作,就生成了一个镜像。
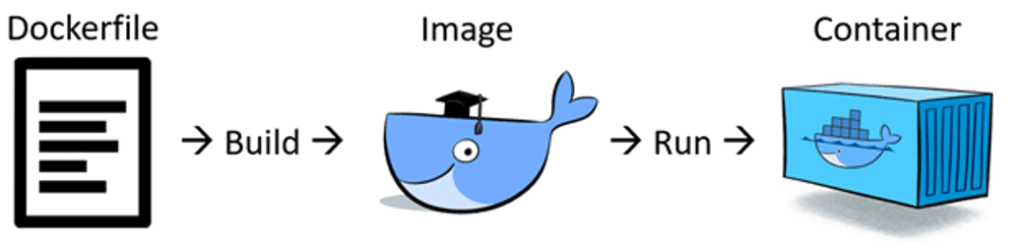
镜像是一个文件?
镜像从逻辑上可以简单理解是一个文件,但实际上是多层文件的组合。
所以,镜像虽然不是一个单独的文件,但可以被导出成为一个压缩文件:
# 镜像导出成一个tarball文件
docker save image
# 加载一个 tarball 镜像文件
docker load image
镜像存放在哪里?
运行容器时,Docker 会从 /var/lib/docker/image 目录下寻找是否镜像文件。
如果没有镜像文件,Docker 会尝试从 Dockerhub 镜像仓库中下载到本地,然后运行。
仓库
众所周知,DockerHub 是由 Docker 官方运营的全球最大的镜像仓库。
实际上,除了 DockerHub 之�外,还有多种构建仓库的方式:
自建仓库
支持自建仓库。一般云提供商均提供了镜像仓库服务,供客户存放自己的私有镜像。
其他公开仓库
容器
容器是 Docker 最重要的组件,上面已经多次提到容器就是一个轻量级虚拟机。
运行
通过 docker run 命令运行容器,它的用法和参数如下(详情)。
下面我们通过一个简单的示例,介绍如何运行��一个容器:
- 找到一个 Docker 镜像,例如:MySQL
- 运行如下的命令启动一个 MySQL 容器
docker run --name mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:tag - 容器运行成功后,运行如下命令即可开始使用 MySQL 的客户端命令
docker exec -it mysql mysql -uroot -p123456
上述示例我们完成如下几个工作:
- 通过镜像页面找到运行容器的方案
- 运行一个容器
- 进入一个容器
保存
容器也可以很方便的转换成镜像。具体操作如下:
-
运行
docker ps命令获取容器的 ID 号 -
将容器导出为压缩文件
# 容器导出成 tarball 文件
docker export -o mysql-`date +%Y%m%d`.tar f9fc8627b7fe
# 查看文件
ls mysql-`date +%Y%m%d`.tar -
将压缩文件转换成镜像
docker import mysql-20210416.tar mysql-test -
运行
docker image ls命令,查看刚转换成功的镜像$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
mysql-test latest 05cb947f5572 5 seconds ago 209MB
从功能上讲,docker export相当于commit +save,先将容器commit成镜像,再 save 成文件。
数据卷
Docker 容器的理念是运行时,因此它并不向普通的虚拟机一样,可以方便的更改任何文件。
但用户在实际使用 Docker 的过程中,一定有持久保存数据(包含配置文件)的需求,那么 Docker 是如何解决这个问题的呢?
概述
Docker 提供了一套数据存储的方案(卷):
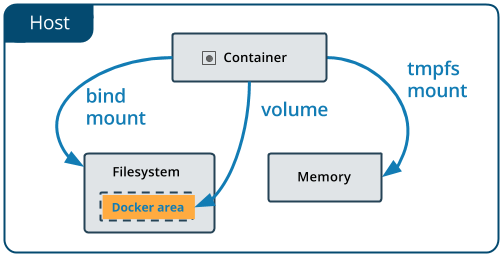
主要有两种形式的存储卷模式:
| Named Volumes | Bind Mounts | |
|---|---|---|
| 路径 | /var/lib/docker/volumes 目录下 | 任意位置 |
| 启用方式 | my-volume:/usr/local/data | /path/to/data:/usr/local/data |
| 预先定义 | 可以先定义,也可以不定义 | 不需要 |
| 名称 | my-volume_default 或 my-volume | data |
| 文件权限 | 权限宽松 | 受制于宿主机文件权限 |
| 空目录下数据方向 | 容器 → Named Volume | Bind Volume → 容器 |
| 非空目录下数据方向 | Named Volume → 容器 | Bind Volume → 容器 |
我们根据持久化数据挂载的几种场景进行试验,得出如下的现象:
- 容器启动后由 CMD 和 ENTRYPOINT 产生的数据区别于镜像中 COPY/ADD 层的数据,前者我们称之动态数据,后者为静态数据。显然,动态数据不受挂载影响。
- 宿主机目录优先定律:挂载双方都有数据时,宿主机目录覆盖容器目录
- Bind Mounts 与 Named Volumes 有差异:Bind Mounts 任何情况下都会覆盖容器目录,而 Named Volumes 挂载空目录时会先拷贝容器目录的数据
Named Volumes 在 Docker 中被推荐为首选方式,它与 Bind Mounts 相比,有以下优点:
- 与 Bind Mounts 相比,Named Volumes 更容易备份或迁移。
- 可以使用 Docker CLI 命令或 Docker API 来管理。
- Named Volumes 在 Linux 和 Windows 容器上都能工作。
- Named Volumes 可以在多个容器之间更安全的共享。
- Named Volumes 驱动程序允许你在远程主机或云上提供存储、加密或其他功能。
- 新 Named Volumes 的内容可以由容器预填充。
使用卷
下面是一个通过 -v 使用卷的范例:
docker run -dp 3000:3000 \
-w /app -v "$(pwd):/app" \
node:12-alpine \
sh -c "yarn install && yarn run dev"
共享卷
多个容器共享一个存储卷是非常典型的应用场景:
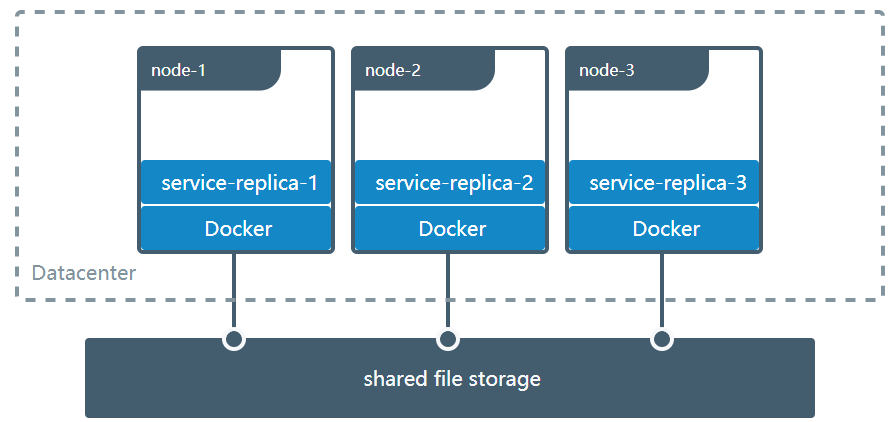
网络
由于容器是用于部署应用的,因此它需要频繁的被其他服务所访问,深刻理解 Docker 网络的概念和原理就显得至关重要。
组网
对于Docker系统来说,默认有一个容器路由功能,简单的说,Docker会给每个部署好的Container生成一个内网IP地址。例如,Docker下运行了容器,Docker就自动分配了3个内网地址:
容器1 172.18.0.1
容器2 172.18.0.2
容器3 172.18.0.23
对于其中任何Container来说,都可以通过IP地址作为访问通道
端口
每个Container,都可以映射到服务器的一个端口上,以便于外部访问这个Container。 例如:172.18.0.1 上运行了MySQL,且MySQL本身开启了外部访问。这个时候,如何通过服务器的IP地址来访问这个MySQL呢?
-
首先,将容器1的做一个端口映射,加入映射到都服务器的3306端口
-
然后,通过 服务器IP:3306 就可以访问MySQL
问题:Container中的应用为什么有端口号?Container是带最简的操作系统的,有操作系统就一定会通过端口访问程序
用户
一般来说 Docker 不建议以 root 用户运行容器进程,因此 Dockerfile 的编写者都会在代码中创建普通用户,然后以普通用户运行进程。
如果没有创建普通用户,容器就会默认以 root 用户权限运行
容器的 root 与宿主机的 root 是同一个用户,但容器 root 的权限是有限的,如果加上 --privileged=true,那么它就等同于宿主机 root 权限
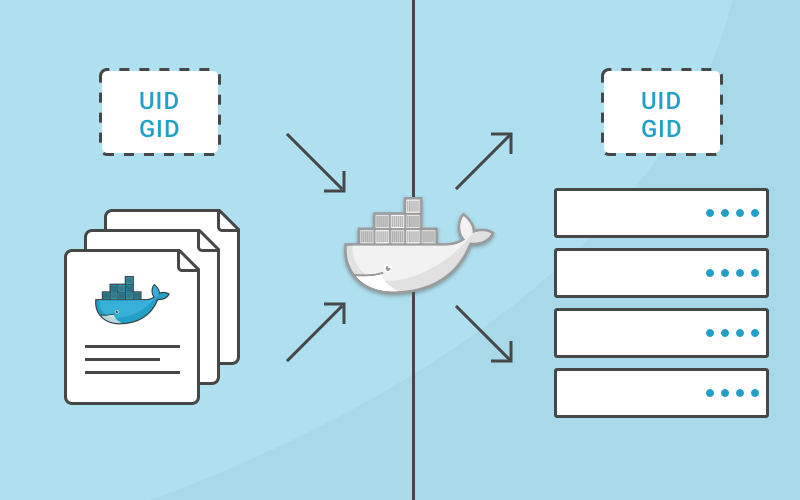
UID
虽然有用户名的概念,但由于 Linux 内核最终管理的用户对象是以 uid 为标识,所以本节均以 uid 来替代用户名。
容器由于是基于虚拟隔离技术的并共享操作系统内核的独立进程,而内核只管理一套 uid 和 gid,所以容器中的 uid 和 gid 实际上与宿主机内核是一套体系。
理解容器中用户权限、uid、gid 等本质,重点在于理解 《Linux User Namespace》
当容器进程尝试写文件时,内核会检查此容器的 uid 和 gid,以确定其是否具有足够的特权来修改文件。
提权
我们在 Dockerfile 会发现,当需要对用户提权的时候,采用的不是 su,而是下面两个命令的组合
- gosu
- exec
进程
有人说,容器的本质就是进程。不管这句话是否绝对,但可见进程对于容器的重要性不言而喻。
查询进程
通过运行 docker top containerid 查询进程。
为了便于理解,我们先运行一个Docker应用:docker-wordpress
然以后分别查询各个容器的进程。
[root@test ~]# docker top wordpress-mysql
UID PID PPID C STIME TTY TIME CMD
polkitd 22107 22080 0 Aug01 ? 00:01:52 mysqld
[root@test ~]# docker top wordpress
UID PID PPID C STIME TTY TIME CMD
33 807 22090 0 Aug01 ? 00:00:00 apache2 -DFOREGROUND
33 1675 22090 0 Aug01 ? 00:00:01 apache2 -DFOREGROUND
33 2935 22090 0 Aug01 ? 00:00:00 apache2 -DFOREGROUND
33 21955 22090 0 Aug01 ? 00:00:00 apache2 -DFOREGROUND
root 22090 22054 0 Aug01 ? 00:00:06 apache2 -DFOREGROUND
33 26327 22090 0 Aug01 ? 00:00:00 apache2 -DFOREGROUND
33 28793 22090 0 Aug01 ? 00:00:01 apache2 -DFOREGROUND
33 30253 22090 0 Aug01 ? 00:00:00 apache2 -DFOREGROUND
33 31445 22090 0 Aug01 ? 00:00:01 apache2 -DFOREGROUND
33 31955 22090 0 Aug01 ? 00:00:01 apache2 -DFOREGROUND
33 32734 22090 0 Aug01 ? 00:00:01 apache2 -DFOREGROUND
可见有的容器只运行了一个进程,而有的容器运行了多个进程(Apache 作为HTTP服务器,其天生是多进程设计)。
也可以进入其中一个容器,再运行 ps -ef 命令查看进程:
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 Aug01 ? 00:00:06 apache2 -DFOREGROUND
www-data 153 1 0 Aug01 ? 00:00:01 apache2 -DFOREGROUND
www-data 181 1 0 Aug01 ? 00:00:00 apache2 -DFOREGROUND
www-data 193 1 0 Aug01 ? 00:00:01 apache2 -DFOREGROUND
www-data 209 1 0 Aug01 ? 00:00:01 apache2 -DFOREGROUND
www-data 214 1 0 Aug01 ? 00:00:01 apache2 -DFOREGROUND
www-data 215 1 0 Aug01 ? 00:00:00 apache2 -DFOREGROUND
www-data 218 1 0 Aug01 ? 00:00:01 apache2 -DFOREGROUND
www-data 219 1 0 Aug01 ? 00:00:00 apache2 -DFOREGROUND
www-data 224 1 0 Aug01 ? 00:00:00 apache2 -DFOREGROUND
www-data 225 1 0 Aug01 ? 00:00:00 apache2 -DFOREGROUND
root 253 0 0 06:17 pts/0 00:00:00 bash
root 261 253 0 06:18 pts/0 00:00:00 ps -ef
可见,两者的效果是一样的。
新开一个 Shell 窗口,再运行 pstree -a 命令,回看到如下的进程树
├─containerd-shim -namespace moby -id 8a7712fe435afaa79c08e7281de7e1a658cd00261fecc7ba02da1847d47d1715 -address /run/containerd/containerd.sock
│ ├─apache2 -DFOREGROUND
│ │ ├─apache2 -DFOREGROUND
│ │ ├─apache2 -DFOREGROUND
│ │ ├─apache2 -DFOREGROUND
│ │ ├─apache2 -DFOREGROUND
│ │ ├─apache2 -DFOREGROUND
│ │ ├─apache2 -DFOREGROUND
│ │ ├─apache2 -DFOREGROUND
│ │ ├─apache2 -DFOREGROUND
│ │ ├─apache2 -DFOREGROUND
│ │ └─apache2 -DFOREGROUND
│ ├─bash
│ └─12*[{containerd-shim}]
├─containerd-shim -namespace moby -id d287c79eaced1fcdde94b2b6d45781937cb17a0ddf4848d26907dee40602e80f -address /run/containerd/containerd.sock
│ ├─mysqld
│ │ └─30*[{mysqld}]
│ └─13*[{containerd-shim}]
你会发现,这个查询结果也基本类同。
创建进程
通过上面的说明,我们已经有了非常具体的进程印象,那么现在我们再深入一些:容器的进程是如何创建的呢?
我们先回顾 Dockerfile 中的 CMD 和 ENTRYPOINT,其他它就是容器的运行时,镜像提供了容器运行所需的软件包和软件环境,但如果不通过 CMD 和 ENTRYPOINT 来启�动各种应用,容器就不会产生进程。
非服务进程
容器一般的用于承载服务,但在开发中,容器镜像也可以用作短暂的进程:在我们计算机上运行的、容器化的可执行命令。这些容器执行单一的任务,生命周期短暂,而且通常可以在使用后被删除。我们称之为可执行镜像,这样的镜像创建的容器的进程可以称之为非服务进程。
主进程
在Docker中有一个很特殊的进程(PID=1 的进程),这也是Docker的主进程,通过 Dockerfile 中的 ENTRYPOINT 和/或 CMD指令指定。当主进程退出的时候,容器所拥有的 PIG 命名空间就会被销毁,容器的生命周期也会结束 Docker 最佳实践建议的是一个 container 一个 service,并不强制要你一个container一个线程。有的服务,会催生更多的子进程,比如 Apache 和 uwsgi,这是完全可以的。
PID1进程需要对自己创建的子进程负责,当主进程没有设计好,不能优雅地让子进程退出,就会照成很多问题,比如数据库 container,如果处理数据的进程没有优雅地退出,可能会照成数据丢失。如果很不幸,你的主进程就是这种管理不了子进程的那种,Docker 提供了一个小工具,帮助你来完成这部分内容。你只需要在 run 创建 container 的时候提供一个 —init flag 就行,Docker 就会手动为你处理好这些问题。
Docker 的主进程由于是一个很特殊的存在,它的生命周期就是 docker container 的生命周期,它得对产生的子进程负责,在�写 Dockerfile 的时候,务必明确 PID1 进程是什么。
编排与集群
编排就是将多个运行的容器串联起来,最常见的编排工具是 Docker Compose。
Docker Compose 的知识点包括:
- Docker Compose 命令行
- Docker Compose 文件编写
容器不仅仅可以运行在单台宿主机上,它也支持运行在多个主机,有两种类型的流行集群工具:
- Docker Swarm:Docker 官方出品的容器的集群和调度工具。借助 Swarm,IT 管理员和开发人员可以将 Docker 节点集群建立和管理为单个虚拟系统。
- Kubernetes(k8s):跨主机集群的自动部署、扩展以及运行应用程序容器的开源平台。
常见问题
如何给容器赋予宿主机的 root 权限?
privileged: true
容器中哪些文件夹可以被挂载?
原则上 Dockerfile 声明的 VOLUME 方可被挂载
Compose 中定义一个公用的网络?
可以(仅 3.1 以上可用),代码如下:
networks:
default:
name: "apps"
去掉 Named volume 挂载的前缀名?
Named volume 挂载的目录名称默认为 {project_name}_dirname。这样做的好处是避免多个同类应用挂载导致冲突。
如何去掉这个前缀呢?下面是具体的范例:
- 先创建一个挂载点
docker volume create --name=graylog
- Docker-compose 文件中 volumes 定义中增加
external: true参数
volumes:
graylog:
external: true
容器是否可以跨网络通过主机名互联?
只有 link 后的容器才可以
不知道容器所需的端口怎么办?
建议开启【Publish all exposed network ports...】 以保证容器中的服务可以自动匹配服务器端口被外界访问。如果不开启,需自行到DockerHub网站查看端口。
容器的端口与服务器的端口有什么区别?
容器端口需要通过服务器端口做映射,才可以被互联网用户访问。
单台服务器上是否可以跑多个容器?
只要服务器资源允许,单台服务器上可以运行成百上千个容器
什么是Docker的C/S模式?
Docker安装后,在宿主机(服务器)端会运行一个 Docker Daemon 守护进程,同时也安装一个Docker客户端与这个守护进程通信。但客户端与守护进程是分离的,即可以在任何地方运行客户�端,然后通过远程与守护进程通信。
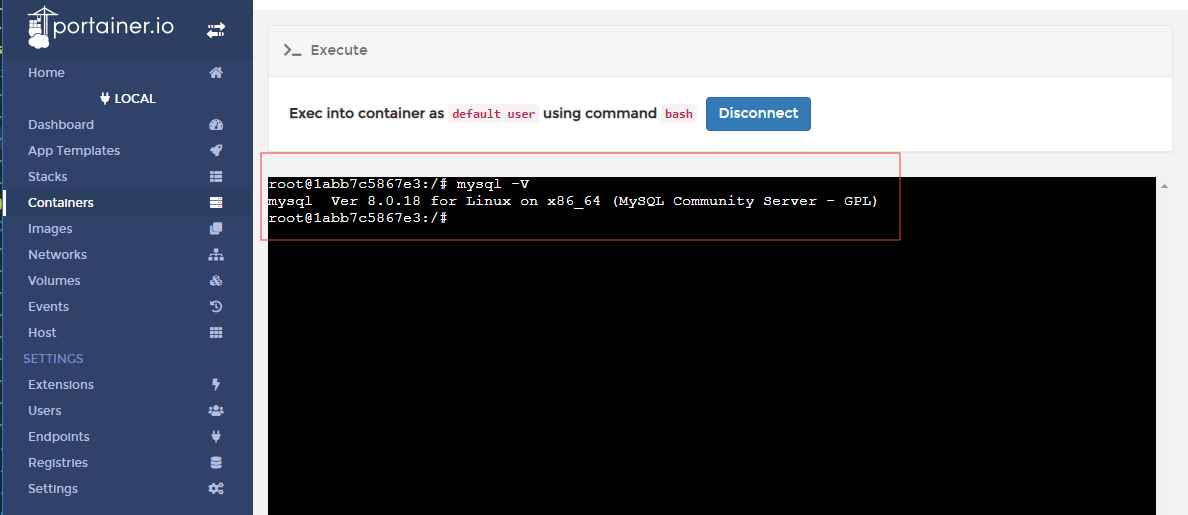
是否可以通过SSH连接容器?
在Container上的 console 控制台可以很方便的使用命令操作
一个容器中可以运行多个应用吗?
可以。但是从微服务架构角度看,建议一个容器运行单个应用或单个进程
容器中的服务是否可以被互联网访问?
通过与宿主机(服务器)进行端口映射,实现被互联网用户访问
是否有可视化的 Docker 管理工具?
有,推荐使用 Portainer
多个 compose 下有同名的数据库服务名称会怎么样?
首先,这种情况不影响 compose 运行。但使用服务名称(例如:mysql) 已经无法连接任意一个数据库,需使用 appname-db 这种唯一的容器名称。
是否可以修改 Docker 根目录?
可以,但不建议修改
容器与镜像在文件层面的关系?
Docker 的原理表明:容器有一部分被称之为不变的文件,它共享的是镜像的文件,另外一部分是可变文件。
Docker-compose 编程中如何复用代码?
有如下几种复用代码的途径:
- configs 指令:共享一个外部配置文件
- yml 标准语法的 x 替换:在 compose 文件中定义公共代码片段,此语法规则来源于 yml 格式,非 docker 语法
- 多个 compose 文件复用:可以组合复用,也可以 A.yml extend one service from B.yml 这种方式复用