Kafka Maintenance
This chapter is special guide for Kafka maintenance and settings. And you can refer to Administrator and Steps after installing for some general settings that including: Configure Domain, HTTPS Setting, Migration, Web Server configuration, Docker Setting, Database connection, Backup & Restore...
Maintenance guide
Backup and Restore
Upgrade
Please refer to the official document: upgrading from previous versions
Kafka cluster
Kafka has excellent big data processing performance. Generally, when Kafka is used, the system data volume is very large. When the data volume increases geometrically, two factors need to be considered: data processing capacity and disaster recovery and backup capacity. Kafka cluster can solve these two problems. Therefore, in reality, most Kafka applications will use Kafka clusters. Kafka cluster structure
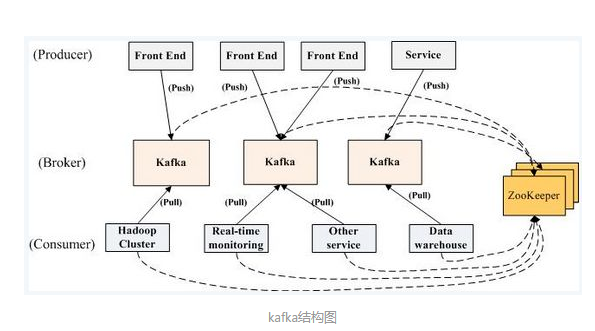
The cluster features in our Kafka cluster scheme are:
- Kafka built a cluster, and zookeeper also built a cluster management Kafka
- Each Kafka node is also a zookeeper node
- The message is connected to the Kafka cluster during production. When consuming, you need to find the offset of the consumption location through zookeeper, and then connect to the Kafka cluster to obtain the message
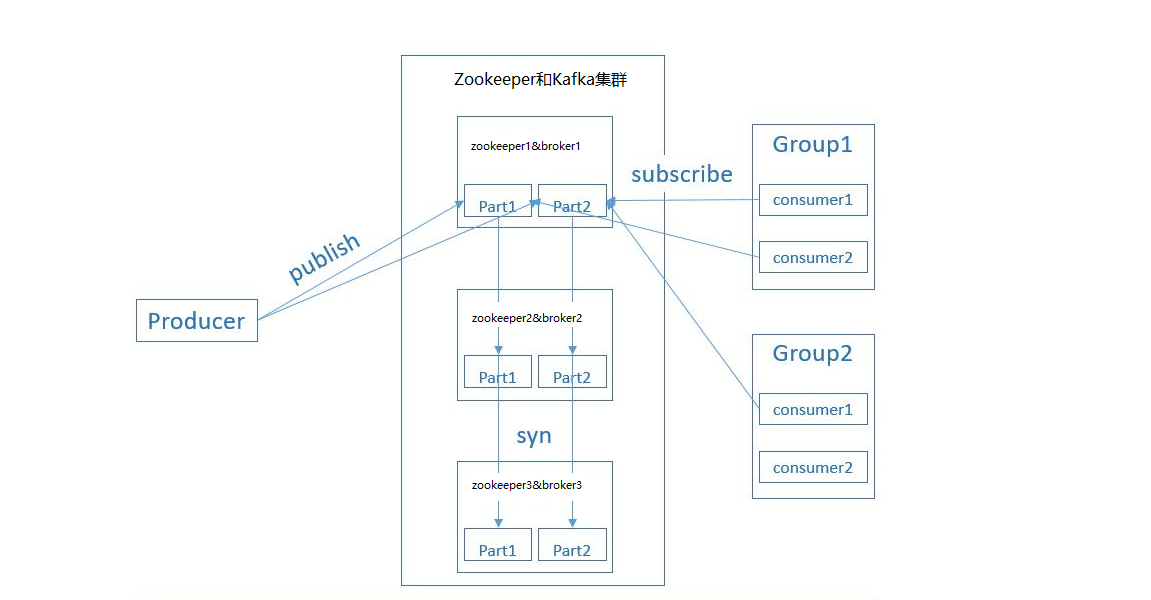
Build zookeeper and Kafka clusters
We can think of the cluster as a whole, and work as an object when connecting to the outside. The specific node needs to work before internal coordination. Therefore, our cluster scheme is to build a node of the cluster first, and then copy the node and modify it. Let's take a node (172.31.57.62) as an example to record the detailed steps: (suppose we use three servers in the LAN (172.31.57.62, 172.31.57.63, 172.31.57.64) to build a cluster.)
- Download [Kafka]( https://archive.apache.org/dist/kafka/2.7.1/kafka_2.13-2.7.1.tgz ), unzip it to / opt and rename it Kafka
- Edit and modify config / zookeeper.properties
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# the directory where the snapshot is stored.
dataDir=/opt/kafka/zookeeper
dataLogDir=/opt/kafka/log/zookeeper
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=0
# Disable the adminserver by default to avoid port conflicts.
# Set the port to something non-conflicting if choosing to enable this
admin.enableServer=false
# admin.serverPort=8080
tickTime=2000
initLimit=10
syncLimit=5
server.1=172.31.57.62:2888:3888
server.2=172.31.57.63:2888:3888
server.3=172.31.57.64:2888:3888
- Enter zookeeper and create ID file
cd zookeeper
echo 1 > myid
- Create zookeeper service and start
[Unit]
Description=Apache Kafka server (broker1)
After=network.target zookeeper.service
[Service]
Type=simple
User=root
Group=root
ExecStart=/opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties
ExecStop=/opt/kafka/bin/zookeeper-server-stop.sh
Restart=on-failure
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl restart zookeeper
- Edit Kafkaconfiguration file
# With the same id
broker.id=1
# Change the IP address to your own
listeners=PLAINTEXT://172.31.57.62:9092
# logs dir
log.dirs=/opt/kafka/logs
zookeeper.connect=172.31.57.62:2181,172.31.57.63:2181,172.31.57.64:2181
- Create Kafka Service and start it
/etc/systemd/system/kafka.service
[Unit]
Description=Apache Kafka server (broker1)
After=network.target zookeeper.service
[Service]
Type=simple
User=root
Group=root
ExecStart=/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
ExecStop=/opt/kafka/bin/kafka-server-stop.sh
Restart=on-failure
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl restart kafka
-
Copy the above node to the server (172.31.57.63), modify the myid in step 3 to 2, the broker.id in step 5 to 2, and the listeners in step 5 to the server address; Other nodes, and so on
-
Note that the display will be normal only after all relevant node servers are started, otherwise an error will be reported
Troubleshoot
In addition to the Kafka issues listed below, you can refer to Troubleshoot + FAQ to get more.
Kafka service can't start?
Run sudo docker logs kafka to view startup status and errors
Run the command "kafka-topics.sh", java not found?
You should add a variable $JAVA_HOME=/usr/bin/java
FAQ
How can I enable the debug mode of Kafka service?
cd /data/apps/kafka && docker compose up
Is it supported to close some partitions on the existing topic?
Not support
Is Java included in this deployment solution?
Yes
Is a web-based GUI management tool for Kafka?
Yes, refer to CMAK
Cannot support the required Kafka version in cmak?
Cmak does not support all Kafka versions. The specific use shall prevail
####Cmak connects kafaka2.4 and the following error is reported?
Error message: yikes! KeeperErrorCode = Unimplemented for /kafka-manager/mutex Try again. (issue) Solution: None
However, in the case of the above error, the zookeeper client can connect to the zookeeper server